【科普】精准医疗与遗传基因检测的行业分析(上)
作者:陈遵秋 陈漪伊
2015-05-07 15:35
编者按:伴随着精准医疗的提出,本已热门的遗传基因检测被越来越多的人提及并关注。自2003年第一个人类基因被测序后(当时花费为30亿美元),由于技术的更新,费用的降低,和基因相关的检测技术及服务开始大量涌现。现如今,已经有上千种的疾病使用到了遗传基因检测 ( Centers for Disease Control and Prevention, 2015)。目前已登记有26,000个实验室检测项目涵盖了5,400种状况和3,700种基因 (NCBI, 2015)。而一个全基因组测序只需6995美元(Skirton, Jackson, Goldsmith, & Connor, 2013),专门针对个体消费者的遗传基因检测只需99美元。一份由United Health Group发布的市场报告(UnitedHealth, 2012)显示,遗传基因检测是实验室检测市场中发展最快的一分支,全美在此上的开支为50亿美元,预计到2021年,可达到150亿至250亿美元。面对这热火朝天的场面,究竟什么是遗传基因检测?有哪些不同种类,能对健康治疗起什么帮助作用?数据分析在其中的角色是什么?在全民参与健康保险的变革时代,美国保险业对遗传基因检测又是怎么对待?现阶段,大众又是如何看待此类检测的?本文作者陈氏夫妇为生物医药大数据分析行业的顶尖专业人士,在美国从事相关的理论模型构建与实战研究多年,现在从专业角度对此相关概念进行阐述,即使资本市场对此概念火热追捧,但也没有多少人真正明了这些基本理论和实际的应用。不过期望能促进有兴趣者对此深入了解,更希望抛砖引玉,能有更多的专业人士进一步阐述和探讨,也就达到目的了。
一、什么是遗传基因检测
遗传基因检测(genetic and genomic testing)是使用实验室方法来看从你父母那儿遗传得来的DNA指令:即你的基因。它可以用来确定健康问题上增加的风险,选择治疗,或者评估对治疗的反应。
遗传检测(Genetic testing)通常使用于遗传性疾病方面,用以检测某些与特定疾病发生相关联的基因(易感基因),进而判断患上此疾病的风险系数。比如,众所周知,一个变异的BRCA1 或 BRCA2基因的存在,会增加本人得乳腺癌或卵巢癌的风险。而基因检测(Genomic testing) 通常只涉及到癌症肿瘤本身。它主要用于给病患和医生提供关于某个特定癌症肿瘤的具体信息:比如,对于某些肿瘤需要加大治疗力度;而对于“表现温和”的肿瘤,可以选择比较温和妥当的治疗方式。进而还引出了两个热词,肿瘤靶向治疗和个体化治疗,乔布斯患有胰腺癌(恶性程度最高的一种癌症)就是综合采用了各种方法,延续了9年生命,并且生活质量较好。
本文采用的定义是前者,即遗传检测,但基因是检测中的一个必不可少的组成部分,所以笼统称为遗传基因检测(genetic and genomic test),但不牵扯后者的定义和内容。
二、遗传基因检测的种类和效用
那么,现在究竟有哪些类型的遗传基因检测?它们各自的服务目的又是什么?美国国家人类基因研究所提供了7类现已比较普遍的检测及定义。
预测和症状发生前的遗传基因检测:用来发现可能增加个体患病几率的基因变化。这些检测的结果可用于对个体患上某种特定疾病的风险预测,从而可能对个体的生活方式及健康保健的调整有所帮助。
载体检测:用来发现携带有和疾病相关的易感基因的个体。载体本身可能没有任何疾病的显状。但,他们具有把易感基因遗传到下一代的能力。下一代就有可能出现疾病或成为新的载体。有些疾病产生需要的易感基因是必须从父母双方那儿遗传下去的。这种类型的检测对有遗传疾病家族史的个体尤为重要,因为他们对特定的遗传疾病往往有着比正常人更高的风险。
产前检查:用来帮助识别在怀孕期间胎儿是否有某些严重的疾病。
新生儿筛查:用来检查发现出生一到二天的新生儿是否患有会影响健康和今后发展的已知疾病。
药物基因组学检测:用来提供关于特定药物在人体内如何产生作用的信息。这种检测能帮助个体的医疗保健人员根据你的基因构成,选择效果最好的药物。
研究性遗传基因检测:用来更多地了解基因对健康和疾病的贡献。此类研究的结果可能不直接有益于参与者,但它们可以帮助研究人员更好的理解人体,健康和疾病,从而推动医学及健康科学的进步,在今后使他人受益。
三、遗传基因检测是否包查百病?
虽然已有成千上万涵盖了几百种人类疾病和性状的相关联基因被发现,但对于大多数疾病而言,仅仅只有很小一部分的遗传基因被识别出来,更何况,相关联并不表明该基因就是引起疾病的罪魁祸首,即关联性不等同于因果性。
因此,几乎所有复杂的疾病,迄今为止,即使是已知的具有高度遗传性的疾病,现有的遗传基因风险分析往往只能部分解释疾病的发生(Do C., et al., 2012)。比如,对于10种复杂疾病(阿尔茨海默病,双相性精神障碍,乳腺癌,冠状动脉疾病,克罗恩病,前列腺癌,精神分裂症,系统性红斑狼疮,1型糖尿病,2型糖尿病)的发生,只有约0.4% 到31.2%是被已知的易变基因变种所解释了的 (So HC., et al., 2011)。这说明仅凭我们现在已发现的基因,对这些包含遗传因素的疾病的产生进行预测是很不完善的。也就是说,大多数情况下依托单核苷酸多态性(SNP)(可笼统理解为一种DNA基因变异)建立的风险预测模型对于现有已知标记(染色体上一个可以被识别的区域)只能获得较差的预测值(Do C.,et al., 2012)。
因此,在临床上,人们对于使用遗传基因进行疾病的风险预测十分谨慎。此外,基因组学涉及的不仅仅只有基因方面的影响,还有环境方面的影响,也包括了更复杂的基因与基因,基因与环境之间的交互影响等等,从而增加了收集数据并依此建模的复杂性。
四、遗传基因检测里的数据分析
上面提到,使用基因信息所得到的风险预测模型并不理想。那么怎么判断预测模型的好坏呢?这儿就有必要了解一下全基因组关联研究(GWAS) 具体是怎么回事和数据分析是如何应用在里面的。全基因组关联研究又称为常见变种相关性研究(common-variant association study: CVAS)。它是一种针对个体的许多常见共同基因变种的检查,用以判别是否有任何变种与某一性状(比如疾病表现特征)相关联。GWAS通常侧重于研究单核苷酸多态性(SNPs)和一些有性状的主要疾病的关联性。最常见的此类研究方法称为表型检测,即把参与者根据他们的临床表现特征分成两组,比如患者组和健康人口组,然后分别检测并比较他们的SNP。如果某一类型的变种(等位基因)或多或少经常出现在患者组中并被统计验证它出现不是偶然的,该SNP就被认为和此疾病是相关联的。该相关性SNP所标识的人类基因组某一区域就被认为会影响患病的风险。此处再强调一下,相关性不等同于因果性。
通过GWAS研究所发现的与特定疾病有关联性的SNP并不能被认为就会引起或增加患病的风险。而依据基因的风险预测模型就是根据SNP和 疾病相关的强弱程度计算出个体患病风险系数,并在此系数基础上进一步将个体划分入不同患病风险的组别。预测判断精准与否直接影响到个体是被正确划入风险高的组别还是风险低的组别。
最常用的一个判别风险划分精准度的指标,原本是应用在信号检测理论中的叫做:接收者操作特征曲线,receiver operatingcharacteristiccurve,缩写为ROC。曲线下的面积称为Area under curve,缩写为AUC。这两者我们综合起来用于判别风险划分精准度。由于事实上,几乎没有什么预测模型是完美的,因此人们需要计算这个预测模型划分的正确率和错误率。相应的,在此我们来介绍一下四个基本概念: 真实高风险,虚假高风险,虚假低风险,和真实低风险,见图一。在我们知道最后个体患病结果的情况下,通过模型预测分类后估计的风险及非风险个体数量。
图一:
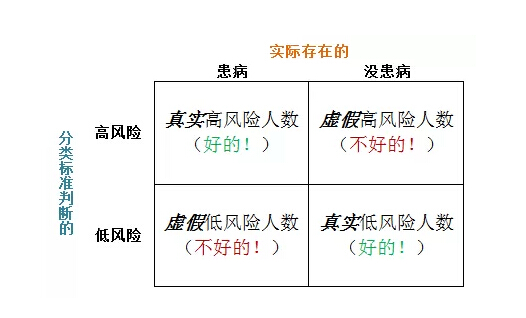
真实风险是真实高风险和真实低风险的总和,也就是归类归对了,被划分为高风险的个人的确患病了,而被划为低风险的人没有得病。虚假风险则是虚假高风险和虚假低风险的总和,即归类归错了。我们通过图二来演示。从左到右,分类标准从十分保守趋向十分激进。左一的小图所设的分类标准要求超高的预测值才能被划入高风险组,从而造就了许多虚假的低风险(即许多被判定为低风险的人最终得病了)。而在右一的小图中,较低的风险预测值就可以被划分为高风险组,从而造就了许多虚假高风险。由此可见,选择分类标准极大地影响了预测模型的最终分类错误率。
图二:
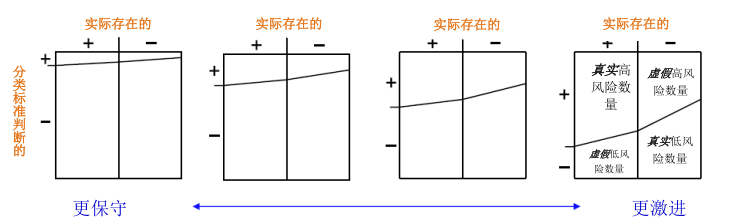
好的分类标准当然是要有尽可能多的真实高风险数量和真实低风险数量,和尽可能少的虚假高风险数量和虚假低风险数量。一般而言,“激进”与否往往取决于个人被归类后,虚假高风险和虚假低风险,哪个会对其造成更严重的医疗健康后果。我们一般通过4个比率来体现一个分类标准的正确率和错误率,如图三和下面的公式所示(后面保险业对遗传基因检测的态度和此有很大关系,所以这儿有必要简单介绍一下):
图三(深色范围是分子,深色+浅色范围是分母):
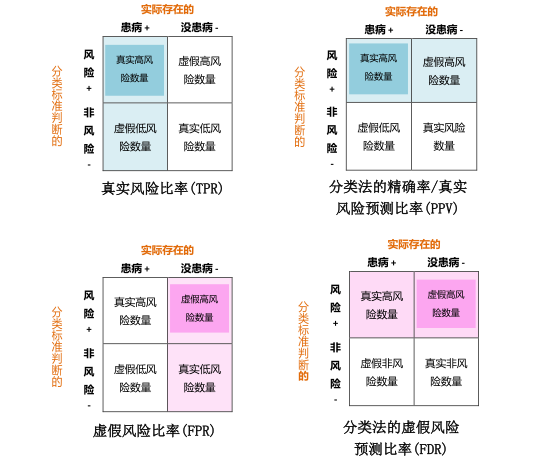

我们希望这些比率的情况是:真实风险比率越高越好,虚假风险比率越小越好,真实风险预测比率越高越好,虚假风险预测比率越小越好。他们数值的范围都是从0到1, 但真实风险比率和真实风险预测比率是1最好。虚假风险比率和虚假风险预测比率是0最好。
下文我们将会继续讨论接收者操作曲线和保险机构对遗传基因检测的实际操作意见,敬请期待。
本文由珍立拍授权动脉网转载。文章为作者独立观点,不代表动脉网立场。




























